Category: Mapping
All topics
-
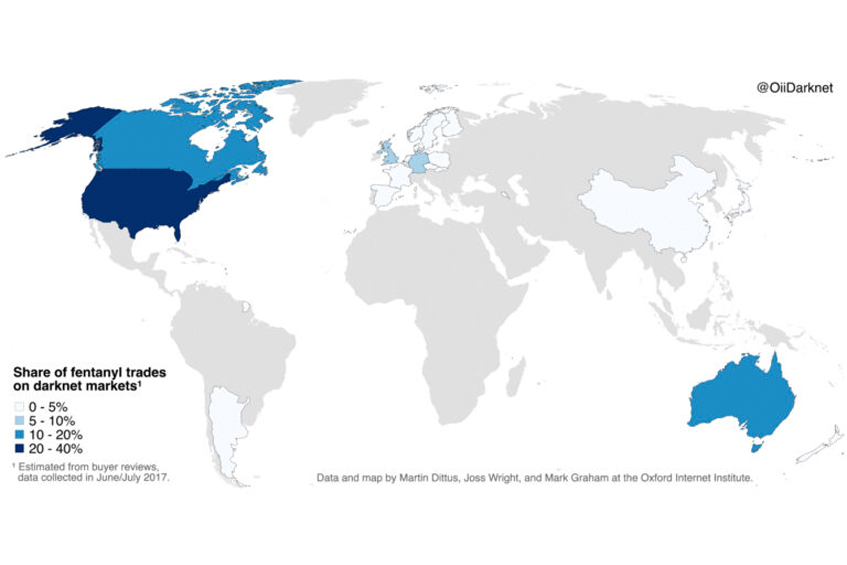
Mapping Fentanyl Trades on the Darknet
The US accounts for almost 40% of global darknet trade, with Canada and Australia at…
-

How useful are volunteer crisis-mappers in a humanitarian crisis?
Concerns have been raised about the quality of amateur mapping and data efforts, and the…
-

After dinner: the best time to create 1.5 million dollars of ground-breaking science
The Zooniverse is a predominant example of citizen science projects that have enjoyed particularly widespread…
-

What explains the worldwide patterns in user-generated geographical content?
As geographic content and geospatial information becomes increasingly integral to our everyday lives, places that…
-

What is stopping greater representation of the MENA region?
Negotiating the wider politics of Wikipedia can be a daunting task, particularly when in it…
-

How well represented is the MENA region in Wikipedia?
There are more Wikipedia articles in English than Arabic about almost every Arabic speaking country…
-

The sum of (some) human knowledge: Wikipedia and representation in the Arab World
Arabic is one of the least represented major world languages on Wikipedia: few languages have…
-

Mapping the Local Geographies of Digital Inequality in Britain
– in MappingWithout detailed information about small areas we can’t identify where would benefit most from policy…
-

Mapping collective public opinion in the Russian blogosphere
The Russian language blogosphere counts about 85 million blogs—an amount far beyond the capacities of…
-

Edit wars! Measuring and mapping society’s most controversial topics
Although some topics are globally debated, like religion and politics, there are many topics which…
-

Who represents the Arab world online?
The Middle East and North Africa are relatively under-represented in Wikipedia. Even after accounting for…
-
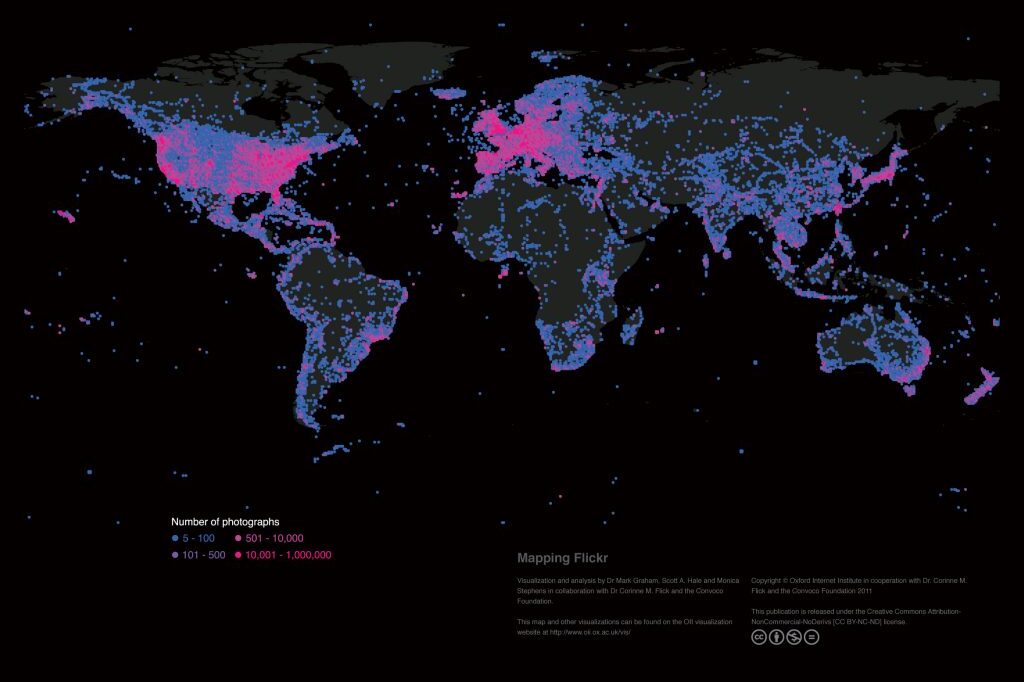
Mapping the uneven geographies of information worldwide
There are massive inequalities that cannot simply be explained by uneven Internet penetration. A range…