Tag: data science
All topics
-

Could Counterfactuals Explain Algorithmic Decisions Without Opening the Black Box?
– in EthicsExploring the role of algorithms in our everyday lives, and how a “right to explanation”…
-

Can we predict electoral outcomes from Wikipedia traffic?
Data show that the relative change in page views to the general Wikipedia page on…
-

Topic modelling content from the “Everyday Sexism” project: what’s it all about?
– in Social Data ScienceHow does the topic modelling algorithm ‘discover’ the topics within the context of everyday sexism?
-

How big data is breathing new life into the smart cities concept
If all the cars have GPS devices, all the people have mobile phones, and all…
-
Digital Disconnect: Parties, Pollsters and Political Analysis in #GE2015
The Oxford Internet Institute undertook some live analysis of social media data over the night…
-
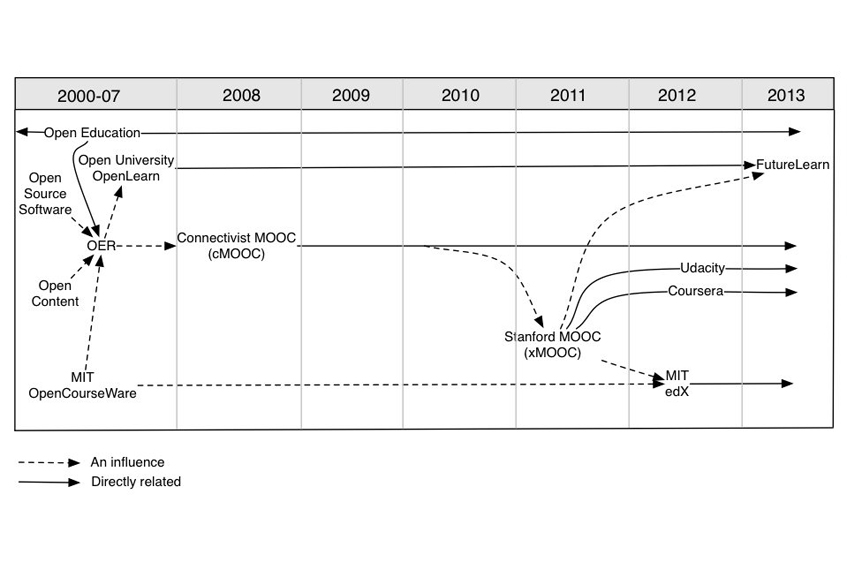
Two years after the NYT’s ‘Year of the MOOC’: how much do we actually know about them?
Despite the hype around MOOCs to date, there are many similarities between MOOC research and…
-

What are the limitations of learning at scale? Investigating information diffusion and network vulnerability in MOOCs
while a lot is known about the mechanics of group learning in smaller and traditionally…
-

The life and death of political news: using online data to measure the impact of the audience agenda
Editors must now decide not only what to publish and where, but how long it…
-

How easy is it to research the Chinese web?
The research expectations seem to be that control and intervention by Beijing will be most…
-

Mapping collective public opinion in the Russian blogosphere
The Russian language blogosphere counts about 85 million blogs—an amount far beyond the capacities of…
-

Technological innovation and disruption was a big theme of the WEF 2014 in Davos: but where was government?
The World Economic Forum engages business, political, academic and other leaders of society to shape…
-

Edit wars! Measuring and mapping society’s most controversial topics
Although some topics are globally debated, like religion and politics, there are many topics which…