Tag: big data
All topics
-

Gender gaps in virtual economies: are there virtual ‘pink’ and ‘blue’ collar occupations?
Men and women tend to be rewarded differently for the same amount of work. Since…
-
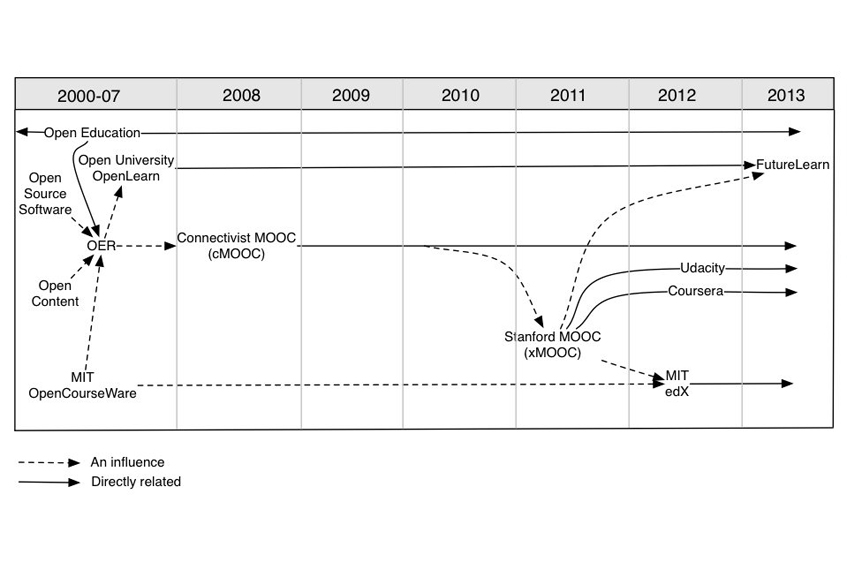
Two years after the NYT’s ‘Year of the MOOC’: how much do we actually know about them?
Despite the hype around MOOCs to date, there are many similarities between MOOC research and…
-

What are the limitations of learning at scale? Investigating information diffusion and network vulnerability in MOOCs
while a lot is known about the mechanics of group learning in smaller and traditionally…
-

Facebook and the Brave New World of Social Research using Big Data
– in Social Data ScienceWhat’s new about companies and academic researchers doing this kind of research to manipulate peoples’…
-

Past and Emerging Themes in Policy and Internet Studies
– in Social Data ScienceIt is simply not possible to consider public policy today without some regard for the…
-

Mapping collective public opinion in the Russian blogosphere
The Russian language blogosphere counts about 85 million blogs—an amount far beyond the capacities of…
-

Edit wars! Measuring and mapping society’s most controversial topics
Although some topics are globally debated, like religion and politics, there are many topics which…
-

The physics of social science: using big data for real-time predictive modelling
There are very interesting examples of using big data to make predictions about disease outbreaks,…
-

Five recommendations for maximising the relevance of social science research for public policy-making in the big data era
How can social scientists help policy-makers in this changed environment, ensuring that social science research…
-

The promises and threats of big data for public policy-making
Widespread use of digital technologies, the Internet and social media means both citizens and governments…
-

Can Twitter provide an early warning function for the next pandemic?
While traditional surveillance systems will remain the pillars of public health, online media monitoring has…
-

Who represents the Arab world online?
The Middle East and North Africa are relatively under-represented in Wikipedia. Even after accounting for…