Category: Social Data Science
All topics
-

The limits of uberisation: How far can platforms go?
Homejoy was slated to become the Uber of domestic cleaning services. It was a platform…
-

Creating a semantic map of sexism worldwide: topic modelling of content from the “Everyday Sexism” project
– in Social Data ScienceWhat are the most common types of sexism globally, and (how) do they relate to…
-

How big data is breathing new life into the smart cities concept
If all the cars have GPS devices, all the people have mobile phones, and all…
-
Digital Disconnect: Parties, Pollsters and Political Analysis in #GE2015
The Oxford Internet Institute undertook some live analysis of social media data over the night…
-

Tracing our every move: Big data and multi-method research
– in Social Data ScienceThere is a lot of excitement about ‘big data’, but the potential for innovative work…
-

After dinner: the best time to create 1.5 million dollars of ground-breaking science
The Zooniverse is a predominant example of citizen science projects that have enjoyed particularly widespread…
-

How can big data be used to advance dementia research?
As dementia is believed to be influenced by a wide range of social, environmental and…
-
Don’t knock clickivism: it represents the political participation aspirations of the modern citizen
Is an action only ‘political’ if it takes place in the mainstream political arena; involving…
-

Gender gaps in virtual economies: are there virtual ‘pink’ and ‘blue’ collar occupations?
Men and women tend to be rewarded differently for the same amount of work. Since…
-
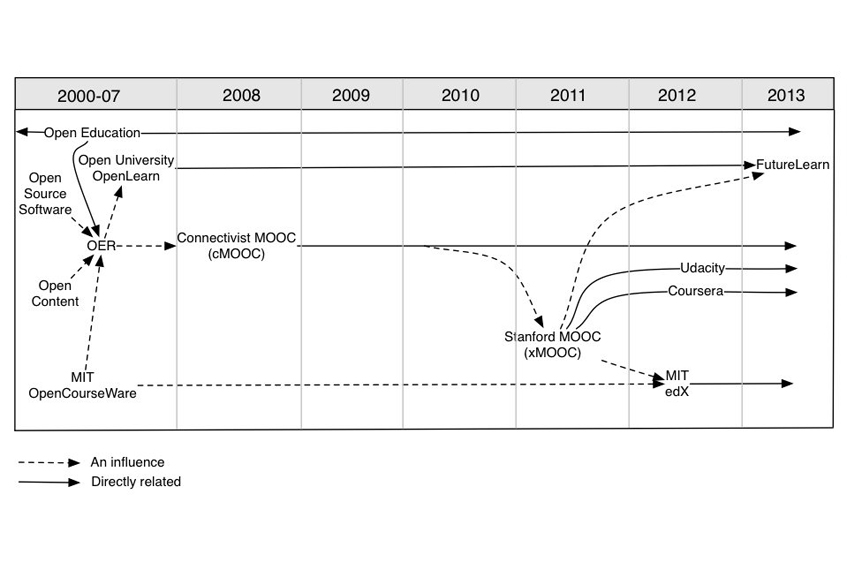
Two years after the NYT’s ‘Year of the MOOC’: how much do we actually know about them?
Despite the hype around MOOCs to date, there are many similarities between MOOC research and…
-

What are the limitations of learning at scale? Investigating information diffusion and network vulnerability in MOOCs
while a lot is known about the mechanics of group learning in smaller and traditionally…
-

Facebook and the Brave New World of Social Research using Big Data
– in Social Data ScienceWhat’s new about companies and academic researchers doing this kind of research to manipulate peoples’…