All Articles
All topics
-

How are internal monitoring systems being used to tackle corruption in the Chinese public administration?
China has made concerted efforts to reduce corruption at the lowest levels of government, as…
-

Seeing like a machine: big data and the challenges of measuring Africa’s informal economies
– in DevelopmentIn a similar way that economists have traditionally excluded unpaid domestic labour from national accounts,…
-

Chinese Internet users share the same values concerning free speech, privacy, and control as their Western counterparts
Many people—even in China—see the Internet as a tool for free speech and as a…
-

Is China changing the Internet, or is the Internet changing China?
By 2015, the proportion of Chinese language Internet users is expected to exceed the proportion…
-

The scramble for Africa’s data
– in DevelopmentAs Africa goes digital, the challenge for policymakers becomes moving from digitisation to managing and…
-

How effective is online blocking of illegal child sexual content?
Combating child pornography and child abuse is a universal and legitimate concern. With regard to…
-

Presenting the moral imperative: effective storytelling strategies by online campaigning organisations
Existing civil society focused organisations are also being challenged to fundamentally change their approach, to…
-
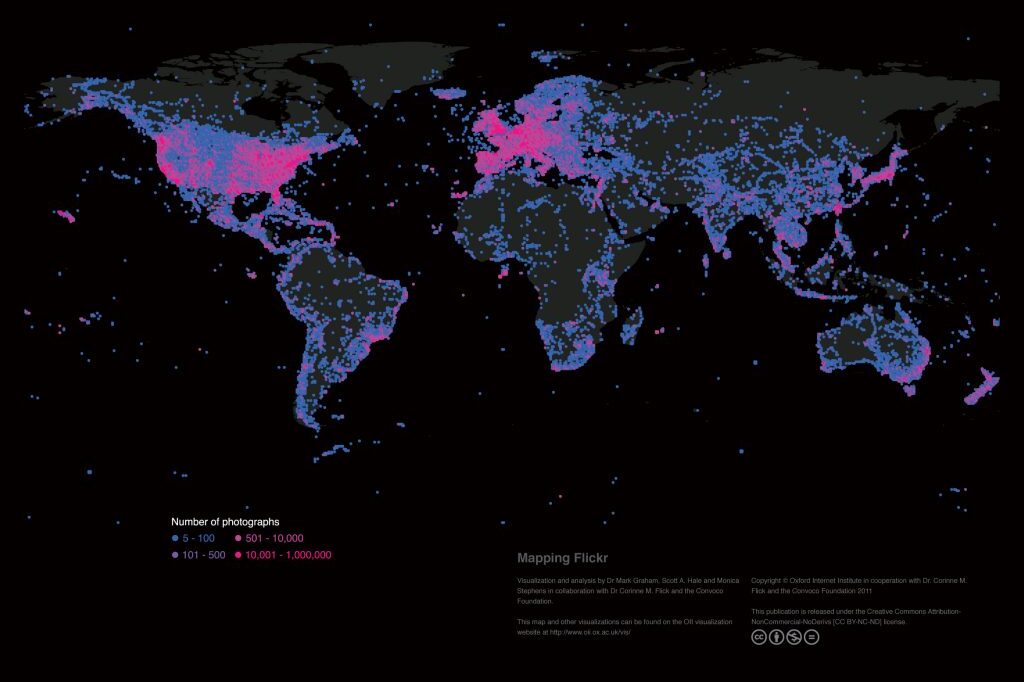
Mapping the uneven geographies of information worldwide
There are massive inequalities that cannot simply be explained by uneven Internet penetration. A range…
-

Investigating the structure and connectivity of online global protest networks
The new networks of political protest, which harness these new online technologies are often described…
-

The global fight over copyright control: Is David beating Goliath at his own game?
We stress the importance of digital environments for providing contenders of copyright reform with a…
-

How accessible are online legislative data archives to political scientists?
Government agencies are rarely completely transparent, often do not provide clear instructions for accessing the…
-

Online crowd-sourcing of scientific data could document the worldwide loss of glaciers to climate change
The platform aims to create long-lasting scientific value with minimal technical entry barriers—it is valuable…