Tag: networks
All topics
-
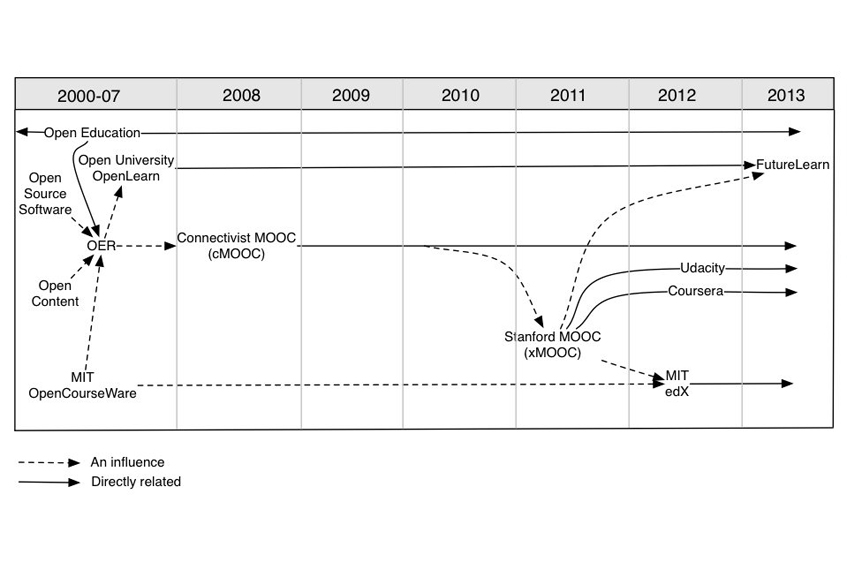
Two years after the NYT’s ‘Year of the MOOC’: how much do we actually know about them?
Despite the hype around MOOCs to date, there are many similarities between MOOC research and…
-

Investigating virtual production networks in Sub-Saharan Africa and Southeast Asia
This mass connectivity has been one crucial ingredient for some significant changes in how work…
-

What are the limitations of learning at scale? Investigating information diffusion and network vulnerability in MOOCs
while a lot is known about the mechanics of group learning in smaller and traditionally…
-
Verification of crowd-sourced information: is this ‘crowd wisdom’ or machine wisdom?
– in Social Data ScienceThe problem with computer code is that it is invisible, and that it makes it…
-

Ethical privacy guidelines for mobile connectivity measurements
Measuring the mobile Internet can expose information about an individual’s location, contact details, and communications…
-

Investigating the structure and connectivity of online global protest networks
The new networks of political protest, which harness these new online technologies are often described…
-

Uncovering the structure of online child exploitation networks
Despite large investments of law enforcement resources, online child exploitation is nowhere near under control,…