Tag: Conversation
All topics
-

Exploring the Ethics of Monitoring Online Extremism
Exploring the complexities of policing the web for extremist material, and its implications for security,…
-
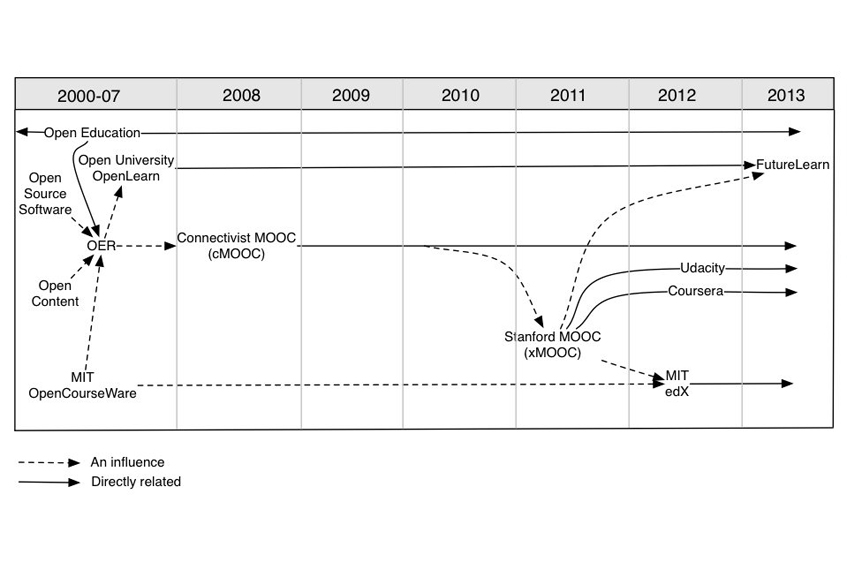
Two years after the NYT’s ‘Year of the MOOC’: how much do we actually know about them?
Despite the hype around MOOCs to date, there are many similarities between MOOC research and…
-

The social economies of networked cultural production (or, how to make a movie with complete strangers)
Looking at “networked cultural production”—ie the creation of cultural goods like films through crowdsourcing platforms—specifically…
-

How easy is it to research the Chinese web?
The research expectations seem to be that control and intervention by Beijing will be most…